
私の切り口からGitを理解しようと思い、Gitの仕組みをあれこれ調べてみました。
道具としてGitを使うという目的だけなら、Gitの細かい仕組みを知らなくても良いのかもしれません。
しかし、Gitについては仕組みをしっかり押さえておきたいと思っていました。
定年退職後、派遣でシステム開発プロジェクトに参加したとき、バージョン管理アプリのコンフリクトが発生したことがありました。
仕組みを理解していなかったため、どのように対応してよいのか分からず、困った経験をしました。
その時のコンフリクトはいつの間にか解消したのですが、イレギュラーな事態が発生したときに正確な対応をするためにも、バージョン管理システムの仕組みを理解しておく必要性を感じていました。
Gitについての疑問点をひとつひとつクリアにして行くことで、Gitの仕組みが明瞭になって行きました。
当ブログでは、そうやって理解した次の内容について掲載します。
フォルダ・ファイル構成
.git(ドットgit)フォルダは、リポジトリのすべての履歴・設定・オブジェクトを管理する中枢ディレクトリです。
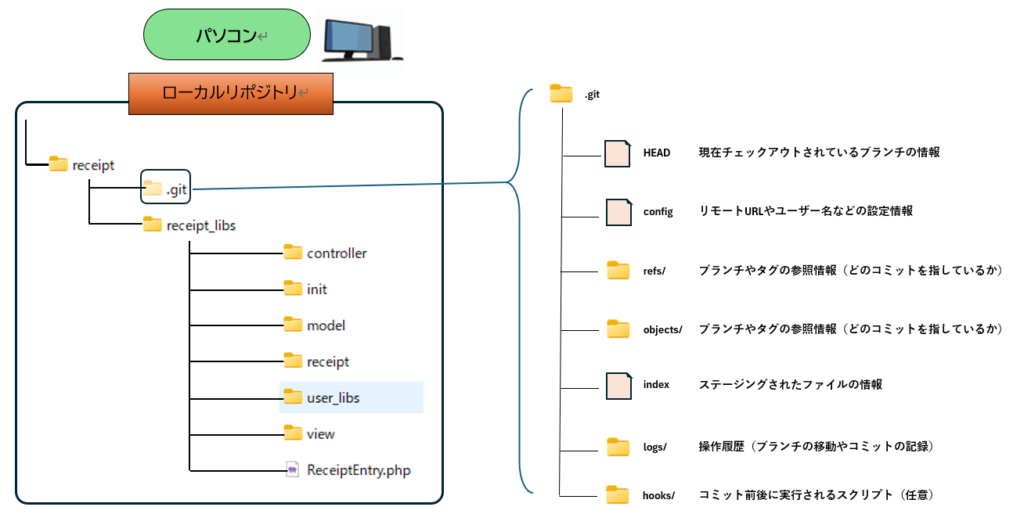
.gitフォルダには以下のファイルとフォルダがあります。
| 名前 | 種類 | 役割・内容 |
|---|---|---|
| HEAD | ファイル | 現在チェックアウトされているブランチ名(またはコミットID)を記録 |
| config | ファイル | Gitの設定情報(ユーザー名、リモートURL、マージ戦略など) |
| description | ファイル | リポジトリの説明(主にベアリポジトリで使用) |
| index | ファイル | ステージングエリアの内容(次のコミットに含めるファイル情報) |
| logs/ | フォルダ | 各リファレンス(HEADやブランチ)の更新履歴を記録 |
| objects/ | フォルダ | Blob、Tree、CommitなどのオブジェクトをSHA-1で保存 |
| refs/ | フォルダ | ブランチやタグの参照情報(heads/, tags/, remotes/) |
| hooks/ | フォルダ | コミット前後などに実行されるスクリプト(自動化や制約に利用) |
| nfo/ | フォルダ | .gitignore の補足情報やエクスクルード設定など |
| packed-refs | ファイル | リファレンスを圧縮して保存するためのファイル(大量のタグなどがある場合) |
| COMMIT_EDITMSG | ファイル | 最後に入力したコミットメッセージ |
| FETCH_HEAD | ファイル | git fetch で取得した最新のリモート情報 |
| MERGE_HEAD | ファイル | マージ中の相手コミットID(マージ操作中のみ存在) |
| ORIG_HEAD | ファイル | リセットやマージ前のHEADのバックアップ |
作業ディレクトリ、ステージングエリア、ローカルリポジトリの実態がどこにあるのを以下に示します。
| 層 | 役割 | 保管場所 |
|---|---|---|
| 作業ディレクトリ (Working Directory) | 実際に編集・作業するファイル群 | プロジェクトフォルダそのもの(例:receipt_libs/) |
| ステージングエリア (Index) | コミット予定の変更を一時的に保持 | .git/index ファイル |
| ローカルリポジトリ (Repository) | コミットされた履歴とオブジェクト | .git/objects/ ディレクトリなど |
git addとgit commit時の動作について
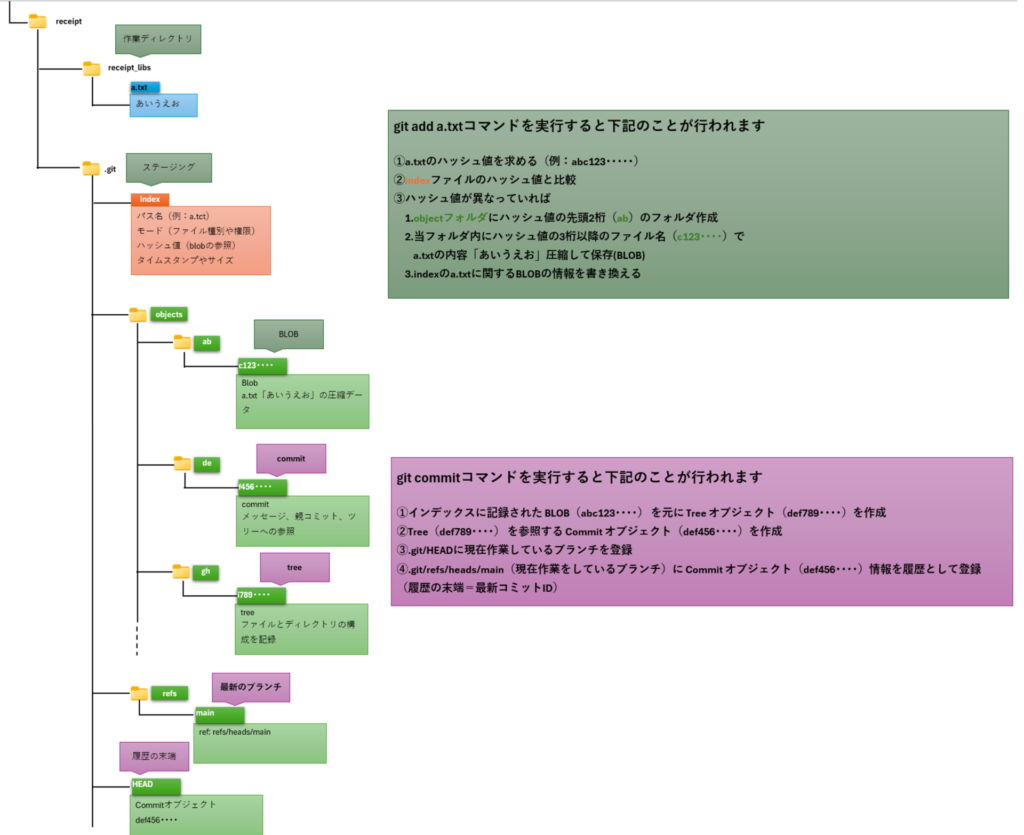
a.txtファイルに「あいうえお」と書き込んで保存し、 git add と git commit を実行した場合を例に説明します。
git add a.txtコマンド実行時の動作
①a.txtの内容でハッシュ値を求める(例:abc123・・・・・)
②indexファイルのハッシュ値と比較(以前addをしていた場合)
③ハッシュ値が異なっているか、あるいは、初回のaddの場合、以下の動作が行われます。
- indexファイルのa.txtに関するBlobの情報を書き換える
- objectsフォルダにハッシュ値の先頭2桁(ab)のフォルダ作成
- 当フォルダ(ab)内にハッシュ値の3桁以降のファイル名(c123・・・・)でa.txtの内容「あいうえお」を圧縮して保存(Blobオブジェクトという)
git commitコマンド実行時の動作
- indexファイルに記録された Blob(abc123・・・・) を元に Tree オブジェクト(def789・・・・)を作成
- Tree(def789・・・・) を参照する Commit オブジェクト(def456・・・・)を作成
- .git/HEADに現在作業しているブランチを登録
- .git/refs/heads/main(現在作業をしているブランチ)に Commit オブジェクト(def456・・・・)情報を履歴として登録(履歴の末端=最新コミットID)
以下に git add と git commit が実行時に生成される成果物の図を示します。
オブジェクトとハッシュの役割について
Gitは、Commit・Tree・Blob・Tagの4種類のオブジェクトと呼ばれるものがあり、各オブジェクトが保持する内容をもとに SHA-1(またはSHA-256)でハッシュ値を計算し、そのハッシュ値をオブジェクトIDとして管理しています。
| オブジェクト | 内容 | ハッシュの役割 |
|---|---|---|
| Blob | ファイルの内容を圧縮して保存 | 内容に対してSHA-1を生成し、保存 |
| Tree | ディレクトリ構成 「ファイル名・パス・モード」と「blobのハッシュ」を記録 | 各ファイルのハッシュと名前を記録 |
| Commit | 履歴情報 「treeのハッシュ」と「メッセージ・日時・親コミット」などを記録 | ツリーのハッシュを含む履歴のハッシュ |
| Tag | バージョンラベル | 対象オブジェクトのハッシュを指す |
階層構造について
オブジェクトは、「ブランチ → Commit → Tree → Blob」 という階層構造になっています。
編集されたファイルの内容(Blob)を履歴に組み込むための道筋が、ブランチ → コミット → Tree → Blob という構造で表現されています。
Gitの「ブランチ → Commit → Tree → Blob」という階層構造は、編集されたファイル(Blob)にたどり着くためのものです。
ブランチ(特定のコミットへのラベル=ポインタ)を起点として、CommitオブジェクトやTreeオブジェクトから履歴と状態をたどってファイルの内容(Blob)に到達します。
下図に各オブジェクトのハッシュ値をたどってファイルの内容(Blob)に到達する例を示します。
ハッシュ値でフォルダ名とファイル名が作成されていることで、ハッシュ値がオブジェクトIDとなってファイルの内容(Blob)へたどり着いていることがよくわかります。

git push時の動作について
git pushが実行されるとアップロード対象の Blob(ファイル内容)を以下のようにして識別して送信(アップロード)します。
- ローカルのブランチ(例:main)の最新コミットIDを確認
- リモートの同じブランチ(origin/main)の最新コミットIDと比較
- 差分の履歴(コミット)をたどり、リモートに存在しないオブジェクトを抽出
- そのコミットに含まれる Tree → Blob を再帰的にたどり、必要な Blob を送信
つまり、ローカルで新しく追加・変更されたファイルの Blob オブジェクトだけが送られるということです。
仮に、a.txt を編集してコミットした場合を例に流れを見ていきましょう。
- git add a.txt → 新しい Blob(ファイル内容)が作成される
- git commit → 新しい Commit と Tree が作成される
- git push → リモートに存在しない Commit, Tree, Blob が送信される
Gitは、リモートにすでに存在する Blob(同じ内容のファイル)は送信しません。
以上、私の疑問点から出発して調べたことをまとめましたが、思い違いをしていることがあるかもしれません。
理解が浅い部分も多々あります。
Gitについては、勉強を継続していきます。
