
スクレイピングの練習の題材として「Amazon領収書」データの抽出を行いました。
ただ、「Amazon領収書」のページはログインセキュリティがかかっているためスクレイピングができません。
そこで、「Amazon領収書」ページのHTMLコードをファイルに出力し、そこから必要な情報を抽出しました。
Webサーバーからのレスポンスではなく、ファイルから読み込んだHTMLですが、スクレイピングの方法は同じです。
練習としてはこれで十分です。
Pythonの開発はJupyter Notebookで行いました。
Jupyter Notebookは、インタラクティブ(対話型で)にプログラムを実行できるwebベースのPythonの環境です。
マシンはWindows10を使いましたが、Jupyter Notebook での開発はMacやLynuxでも同じです。
ブラウザはMicrosoft Edgeを使用しました。
Jupyter Notebookを使うためにはAnacondaをインストールしますが、当ブログではそれについては割愛します。
当ブログでは、今回行った一連の作業を順を追って記述します。
次の7つの作業に分類しました。
1.「Amazon領収書」のページを開き、抽出データを確認する
ブラウザで「Amazon領収書」ページを開き、抽出データを確認します。
2.「Amazon領収書」のページのHTMLコードをファイルに出力する
「Amazon領収書」ページはログインセキュリティがかかっているため、「Amazon領収書」ページのHTMLコードをファイルに出力します。
このファイルのHTML情報を読み込んで、そこから必要な情報を抽出します。
3.HTMLの階層構造を理解する
ブラウザ(EdgeやChromeなど)の開発ツールなどを利用してHTML要素の階層構造を理解します。
複雑なページであれば図にしてみるのが良いと思います。
抽出したいデータをどのような方法で取り出すか検討するための資料として使用します。
4.抽出方法を検討する
目的とするデータへHTMLの要素を検索して辿るか、階層を移動して辿るか、CSSセレクタで辿るかなど、目的とするデータを抽出する方法を検討します。
検討をするときに階層構造を図に表した資料が役立ちます。
辿り着いた文字列から、さらに必要な部分を抜き出したり、フォーマットを変更す必要があれば、その方法も検討します。
5.プログラムコードを記述する
Jupyter NotebookでPythonコードを記述します。
6.データを抽出する
Pythonコードを実行し、データを抽出します。
デバッグを行いながら、プログラムを完成させます。
7.抽出データをCSVファイルに出力する
抽出したデータをCSVファイルに出力します。
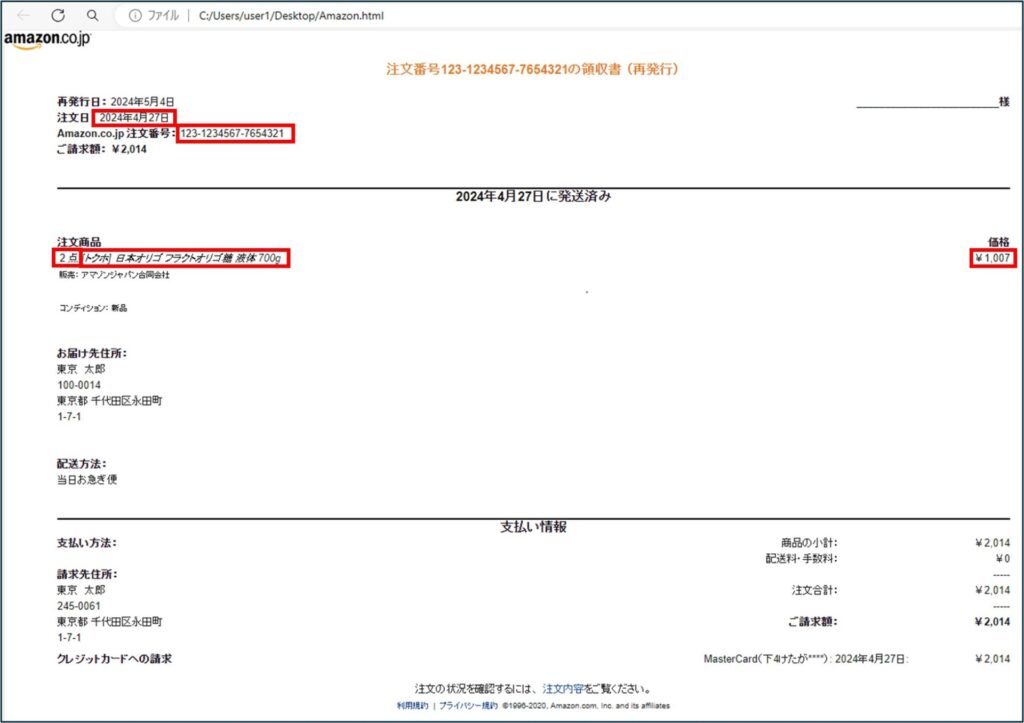
「Amazon領収書」のページを開き、抽出データを確認する
ブラウザで「Amazon領収書」ページを開き、抽出データを確認します。
抽出したいデータは、「注文日」、「注文番号」、「商品名」、「価格(単価)」、「数量」です。
「Amazon領収書」のページのHTMLコードをファイルに出力する
本来であれば「Amazon領収書」ページのWebサイトに直接アクセスしてデータ抽出を行うのですが、ログインセキュリティがかかっているためPythonからアクセスできないので、HTMLコードをファイル(拡張子.html)に出力します。
手順は次の通りです。
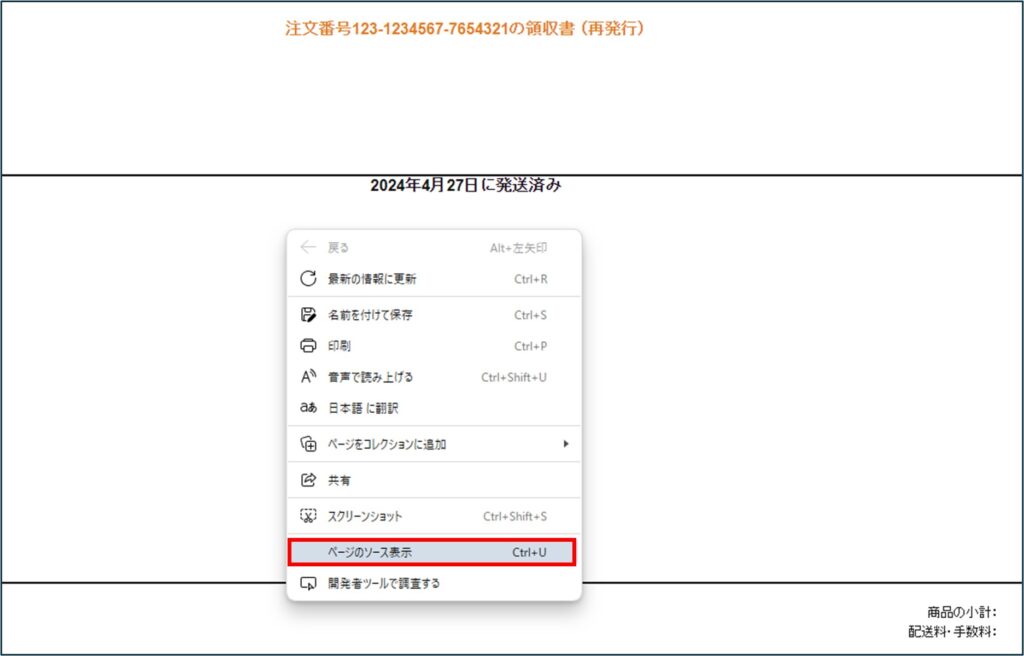
①Edgeで「Amazon領収書」のページを開いたら、表示されているページのどこかにマウスカーソルを置いて、右クリックし、表示されたメニューから「ページのソース表示」をクリックします。
②HTMLソースコードが表示されます。
CTRL+Aで全てのソースコードを選択し、CTRL+Cでコピーします。
③メモ帳を開き、ソースコードをCTRL+Vで貼り付けます。
④メモ帳を保存します。
今回は「C:\Users\user1\Desktop\Amazon.html」で保存しました。
HTMLの階層構造を理解する
階層構造を理解することは、もっとも重要で、一番時間がかかる作業になります。
簡単な構造であれば時間はかからないでしょうが、多くのサイトは階層構造が複雑です。
私はExcelで階層構造を図にしました。
図はこちらのPDFリンクで参照できます。(一部省略しています)
これが、大いに役立ちました。
図の中で緑色に塗りつぶしたところが抽出したいデータです。
抽出方法を検討する
抽出するデータの抽出方法を検討します。
抽出方法は
があります。
目的とするタグに辿り着く方法の検討
まずは、目的とするタグまでどのようにして辿っていくのかを検討します。
Pythonでは次の3つの方法があります。
①find()、find_all()メソッドにより、要素を指定する方法
②HTMLの階層を移動して、要素を指定する方法
③select()メソッドにより、CSSセレクタで要素を指定する方法
※1 今回find_all()メソッドは使用していません。
※2 今回CSSセレクタで要素を指定する方法は使用していません。
「注文日」、「注文番号」、「商品名」、「価格(単価)」、「数量」のそれぞれの要素を辿る方法は次の通りです。
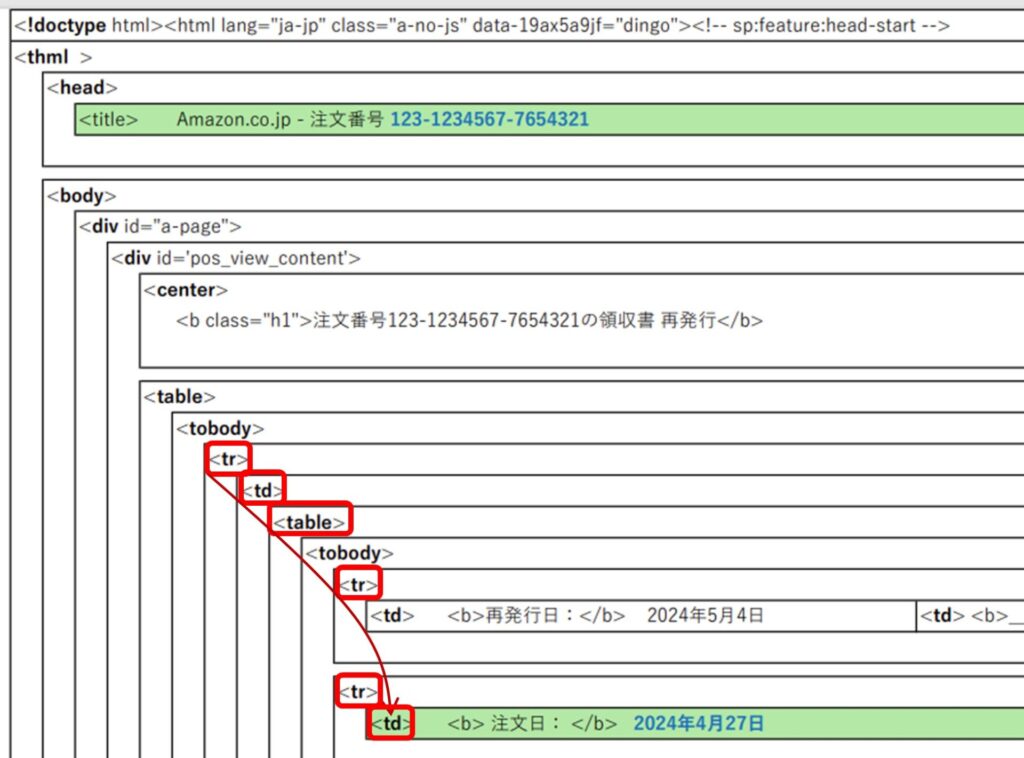
■注文日
最初に出現する<tr>要素を出発点にして注文日のある<td>要素まで辿ります。
Pythonコードは次のようになります。
original_string = soup.tr.td.table.tr.next_sibling.next_sibling.td.text
next_siblingで同一階層にあるtr要素の次の要素へ移動します。
(HTMLの階層を移動して、要素を指定する方法)
■注文番号
<title>要素を指定して辿ります。
Pythonコードは次のようになります。
original_string = soup.find(“title”).text
(find()、find_all()メソッドより要素を指定する方法)

■商品名
<i>要素を指定して辿ります。
Pythonコードは次のようになります。
item_name = soup.find(“i”).text
(find()、find_all()メソッドより要素を指定する方法)

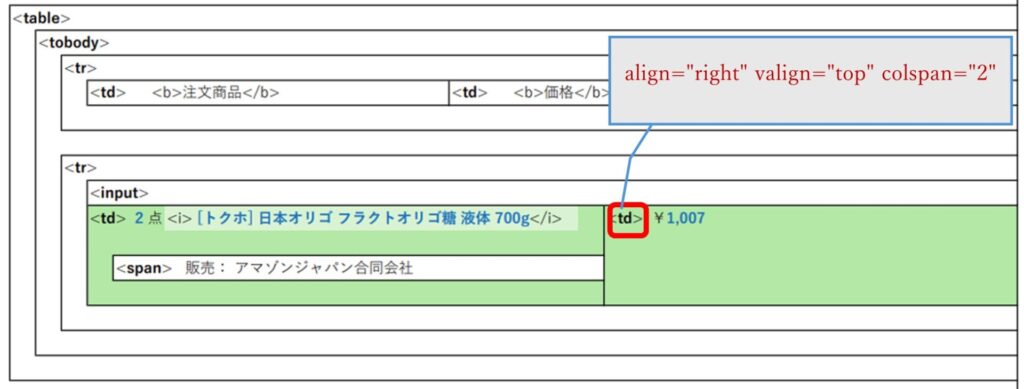
■価格
<td>要素と属性(複数)を指定して辿ります。
Pythonコードは次のようになります。
#辞書として属性をセット 複数の属性がある場合、一旦辞書に登録します
attributes = {‘align’: ‘right’, ‘valign’: ‘top’, ‘colspan’: ‘2’}
#要素(td)と複数属性で検索
pre_price = soup.find(“td”,attrs=attributes)
(find()、find_all()メソッドより要素を指定する方法)
<td align=”right” valign=”top” colspan=”2″>(赤字が属性)
■数量
<td>要素と属性(ひとつ)を指定して辿ります。
属性colspan=”1″を指定しているtd要素は1カ所だけでした。
Pythonコードは次のようになります。
item = soup.find(“td”,colspan=”1″).text
(find()、find_all()メソッドより要素を指定する方法) <td colspan=”1″>(赤字が属性)

辿り着いたタグ内のデータの整形の検討
次に、抽出したデータの整形方法について検討します。
商品名は抽出したデータをそのまま使用できます。
「注文日」、「注文番号」、「価格」、「数量」はそのままでは使用できないので、整形をしました。
今回の例では以下のような整形を行いました。
■注文日
注文日を抽出すると次のようになります。
これを「2024/04/27」の形式で取り出したいので、strip()メソッド、strptime()メソッド、strftime()メソッドを使って整形していきます。
注文日:
2024年4月27日
下記のコードで整形します。
#original_stringに取り出したデータがセットされています
modified_string = re.sub(pattern2, “”, original_string)
#空白文字除去
date_string = modified_string.strip()
#2024年4月27日の部分をpased_dateにセット
parsed_date = datetime.datetime.strptime(date_string, “%Y年%m月%d日”)
#2024年4月27日を2024/04/27に整形
order_date = parsed_date.strftime(“%Y/%m/%d”)
■注文番号
注文番号を抽出すると次のようになります。
これを「999-9999999-9999999」の形式で取り出したいので、正規表現を使って整形していきます。
Amazon.co.jp - 注文番号 123-1234567-7654321
下記のコードで整形します。
# 999-9999999-9999999の数字のパターン
pattern1 = r”\d{3}-\d{7}-\d{7}”
match = re.search(pattern1, original_string)
if match:
order_number = match.group()
print(“注文番号:”,order_number) # 出力: 99-9999999-9999999)
■価格
価格を抽出すると次のようになります。
これを「1,007」の形式で取り出したいので、正規表現を使って整形していきます。
¥1,007
下記のコードで整形します。
#\記号とカンマを除去(pre_price.textの値は\1,007です)
price = re.sub(r’\D’, ”, pre_price.text)
■数量
数量を抽出すると次のようになります。
ここから「2」を取り出したいので、正規表現を使って整形していきます。
2
点
[トクホ] 日本オリゴ フラクトオリゴ糖 液体 700g
販売: アマゾンジャパン合同会社
コンディション: 新品
下記のコードで整形します。
# 文字列内で1つ以上の連続した最初の数字を検索(itemには取り出したデータがセットされています)
pattern3 = r”\d+”
match = re.search(pattern3, item)
if match:
order_quantity = match.group()
print(“数量:”,order_quantity)
プログラムコードを記述する
Jupyter Notebookでプログラムコードを記述します。
利用するライブラリは以下のとおりです。
| ライブラリ名 | 概要 |
|---|---|
| BeautifulSoup | Beautiful Soup 4 (bs4)は、サードパーティー製のHTMLパーサライブラリです。 HTMLやXML構造を持つデータを解析し、プログラムで扱えるようなデータ構造の集合体に変換する役割を果たします。 ウェブスクレイピングやデータ収集の際に、HTMLファイルやXMLファイルからデータを抽出するために利用されます。 |
| re | 正規表現 (Regular Expression) の標準ライブラリです。このライブラリは、文字列のパターンマッチングや検索、置換などの操作を行うために使用されます。 |
| datetime | 日付と時間を扱う標準ライブラリです。 |
プログラムコードは次のとおりです。
処理の内容は、コメントを参照してください。
from bs4 import BeautifulSoup
import re
import datetime
import csv #CSVファイル操作用のライブラリ
# ローカルに保存したAmazon.htmlファイルを html に読み込みます(練習のため)
# Webサイトにアクセスする場合は
# html = "https://aaa.bbb.ccc/" のようにURLを代入します
with open('C:/Users/user1/Desktop/Amazon.html', encoding='utf-8') as f:
html = f.read()
# 読み込んだ html に対して parser を適用します
soup = BeautifulSoup(html,"html.parser")
# 注文番号を抽出 titleタグ (find()、find_all()メソッドにより、要素を指定する方法:要素のみ指定)
original_string = soup.find("title").text
pattern1 = r"\d{3}-\d{7}-\d{7}" # 999-9999999-9999999の数字のパターン
match = re.search(pattern1, original_string)
if match:
order_number = match.group()
print("注文番号:",order_number) # 出力: 99-9999999-9999999)
# 注文日を抽出 (HTMLの階層を移動して、要素を指定する方法)
original_string = soup.tr.td.table.tr.next_sibling.next_sibling.td.text #next_siblingで同一階層の次の要素へ移動
pattern2 = r"注文日:"
modified_string = re.sub(pattern2, "", original_string)
date_string = modified_string.strip() #空白文字除去
parsed_date = datetime.datetime.strptime(date_string, "%Y年%m月%d日") #2024年4月27日の部分をpased_dateにセット
order_date = parsed_date.strftime("%Y/%m/%d") #2024年4月27日を2024/04/27に整形
print("注文日:",order_date)
# 商品名を抽出 iタグ (find()、find_all()メソッドにより、要素を指定する方法:要素のみ指定)
item_name = soup.find("i").text
print("商品名:",item_name)
# 単価を抽出 tdタグ 属性'align': 'right', 'valign': 'top', 'colspan': '2'
attributes = {'align': 'right', 'valign': 'top', 'colspan': '2'} #辞書として属性をセット
pre_price = soup.find("td",attrs=attributes)
price = re.sub(r'\D', '', pre_price.text) # \とカンマ(,)を除去
print("単価:",price)
# 数量を抽出 tdタグ 属性colspan="1" (find()、find_all()メソッドにより、要素を指定する方法:要素と属性で指定)
item = soup.find("td",colspan="1").text
pattern3 = r"\d+" # 文字列内で1つ以上の連続した最初の数字を検索
match = re.search(pattern3, item)
if match:
order_quantity = match.group()
print("数量:",order_quantity)
# 抽出データをCSVファイルに書き出します
csv_header = ["注文番号","注文日","商品名","価格","数量"] #項目名をリストにセット
csv_date = datetime.datetime.today().strftime("%y%m%d%H") #ファイル名は今日の日付と時間 amazon_item_2024050915.csv
csv_file_name = "amazon_item_" + csv_date + ".csv"
with open(csv_file_name,"w",errors = "ignore") as file: #書き込みモード
writer = csv.writer(file,lineterminator="\n") #行の最後に改行コードを付加する指定
writer.writerow(csv_header) #項目名を出力
writer.writerow([order_number,order_date,item_name,price,order_quantity])データを抽出する
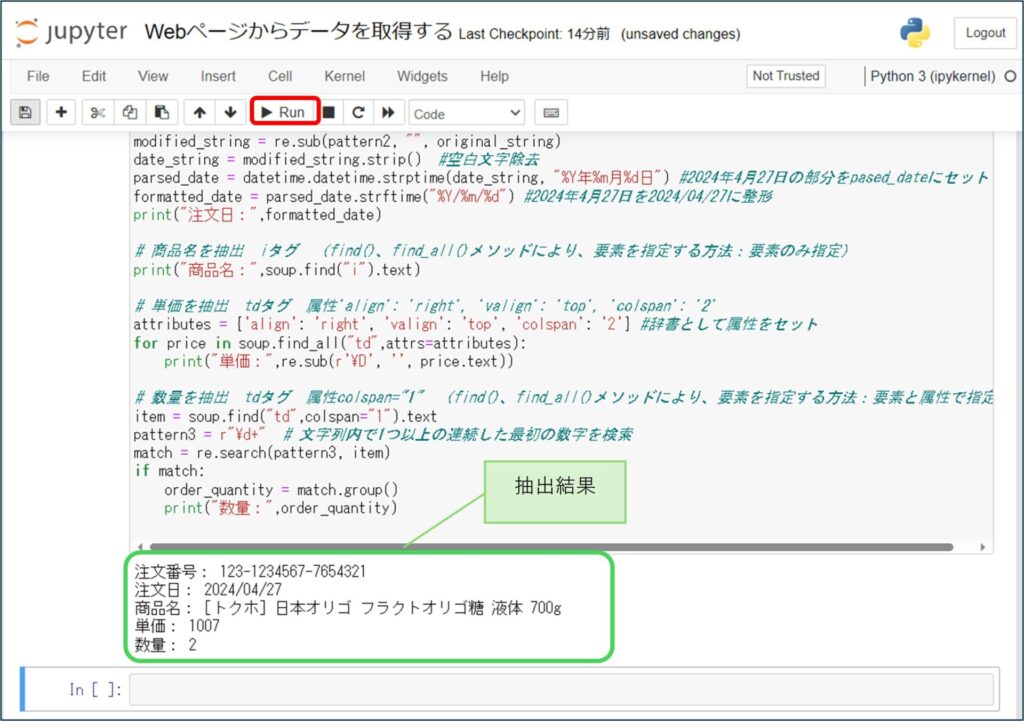
作成したプログラムを実行し、抽出結果を確認します。
[Run]をクリックします。
抽出結果が表示されます。
抽出データをCSVファイルに出力する
抽出結果をCSVファイルに出力します。
csvファイルを扱うために次のライブラリをインポートします。
| ライブラリ名 | 概要 |
|---|---|
| csv | csvファイルを扱う標準ライブラリです。 csv形式のファイルを読み込んだり書き込んだりするために使用されます。 |
先ほどのプログラムコードにimport csvと、csvファイルに書き出すコードを付加します。
コードを付加したら、プログラムを実行し、エクスプローラーでCSVファイルができていることを確認します。

メモ帳などで開き正しく書き出されていることを確認します。

CSVファイルに書き出すコードを付加したプログラムコードを次に示します。
from bs4 import BeautifulSoup
import re
import datetime
import csv #CSVファイル操作用のライブラリ
# ローカルに保存したAmazon.htmlファイルを html に読み込みます(練習のため)
# Webサイトにアクセスする場合は
# html = "https://aaa.bbb.ccc/" のようにURLを代入します
with open('C:/Users/user1/Desktop/Amazon.html', encoding='utf-8') as f:
html = f.read()
# 読み込んだ html に対して parser を適用します
soup = BeautifulSoup(html,"html.parser")
# 注文番号を抽出 titleタグ (find()、find_all()メソッドにより、要素を指定する方法:要素のみ指定)
original_string = soup.find("title").text
pattern1 = r"\d{3}-\d{7}-\d{7}" # 999-9999999-9999999の数字のパターン
match = re.search(pattern1, original_string)
if match:
order_number = match.group()
print("注文番号:",order_number) # 出力: 99-9999999-9999999)
# 注文日を抽出 (HTMLの階層を移動して、要素を指定する方法)
original_string = soup.tr.td.table.tr.next_sibling.next_sibling.td.text #next_siblingで同一階層の次の要素へ移動
pattern2 = r"注文日:"
modified_string = re.sub(pattern2, "", original_string)
date_string = modified_string.strip() #空白文字除去
parsed_date = datetime.datetime.strptime(date_string, "%Y年%m月%d日") #2024年4月27日の部分をpased_dateにセット
order_date = parsed_date.strftime("%Y/%m/%d") #2024年4月27日を2024/04/27に整形
print("注文日:",order_date)
# 商品名を抽出 iタグ (find()、find_all()メソッドにより、要素を指定する方法:要素のみ指定)
item_name = soup.find("i").text
print("商品名:",item_name)
# 単価を抽出 tdタグ 属性'align': 'right', 'valign': 'top', 'colspan': '2'
attributes = {'align': 'right', 'valign': 'top', 'colspan': '2'} #辞書として属性をセット
pre_price = soup.find("td",attrs=attributes)
price = re.sub(r'\D', '', pre_price.text) # \とカンマ(,)を除去
print("単価:",price)
# 数量を抽出 tdタグ 属性colspan="1" (find()、find_all()メソッドにより、要素を指定する方法:要素と属性で指定)
item = soup.find("td",colspan="1").text
pattern3 = r"\d+" # 文字列内で1つ以上の連続した最初の数字を検索
match = re.search(pattern3, item)
if match:
order_quantity = match.group()
print("数量:",order_quantity)
# 抽出データをCSVファイルに書き出します
csv_header = ["注文番号","注文日","商品名","価格","数量"] #項目名をリストにセット
csv_date = datetime.datetime.today().strftime("%y%m%d%H") #ファイル名は今日の日付と時間 amazon_item_2024050915.csv
csv_file_name = "amazon_item_" + csv_date + ".csv"
with open(csv_file_name,"w",errors = "ignore") as file: #書き込みモード
writer = csv.writer(file,lineterminator="\n") #行の最後に改行コードを付加する指定
writer.writerow(csv_header) #項目名を出力
writer.writerow([order_number,order_date,item_name,price,order_quantity])以上、練習で作成した内容をまとめました。
今回は、割と簡単な例題だったと思います。
find_all()メソッドやCSSセレクタで要素を指定して抽出する方法は行っていません。
また、Webサイトからデータを抽出する場合、sleepなどを使ってアクセスのタイミング調整が必要となりますが、今回は行っていません。
様々なサイトからデータ収集を行って、もっと経験を積んでいきたいと思います。

